Python3 爬虫
一. 操作系统
操作系统: Windows 或 Linux均可,安装好Python运行环境,加入环境变量即可。
很Linux发行版默认为Python2,需要再安装Python3,步骤:
以CentOS7 下安装 Python3.7为例:
- 安装依赖包
#yum install zlib* libffi-devel -y
- 下载 Python-3.7.0
#wget https://www.python.org/ftp/python/3.7.0/Python-3.7.0.tgz
#tar -zxf Python-3.7.0.tgz
#cd Python-3.7.0/
- 安装 gcc
#yum insatll -y gcc
- 编译,执行
#./configure --prefix=/usr/local/python3
#make
#make install
- 生成软链接
#ln -s /usr/local/python3/bin/pip3 /usr/bin/pip3
#ln -s /usr/local/python3/bin/python3 /usr/bin/python3/
二. 正则表达式
学习爬虫需要懂得简单的正则表达式的写法:
教程:
[零基础写python爬虫之神器正则表达式 >>][1]
三. 第三方库
- BeautifulSoup
BeautifulSoup是Python的一个库,最主要的功能就是从网页爬取我们需要的数据。BeautifulSoup将html解析为对象进行处理,全部页面转变为字典或者数组,相对于正则表达式的方式,可以大大简化处理过程。
安装
#pip3 install --upgrade beautifulsoup4
BeautifulSoup测试代码:
1#filename: bs4_test.py
2from bs4 import BeautifulSoup
3html = '''
4<html><head><title>The Dormouse's story</title></head>
5<body>
6<p class="title"><b>The Dormouse's story</b></p>
7
8<p class="story">Once upon a time there were three little sisters; and their names were
9<a href="http://example.com/elsie" class="sister" id="link1">Elsie</a>,
10<a href="http://example.com/lacie" class="sister" id="link2">Lacie</a> and
11<a href="http://example.com/tillie" class="sister" id="link3">Tillie</a>;
12and they lived at the bottom of a well.</p>
13<p class="story">...</p>
14'''
15soup = BeautifulSoup(html,'html.parser') #soup = BeautifulSoup(html, 'lxml')
16print(soup.prettify())
17print(soup.title)
18print(soup.title.name)
19print(soup.title.string)
20print(soup.title.parent.name)
21print(soup.p)
22print(soup.p["class"])
23print(soup.a)
24print(soup.find_all('a'))
25print(soup.find(id='link3'))
- lxml
第三方xml解析工具
安装
#pip3 install lxml
四. 写爬虫步骤
- 要明确爬取的网站结构。
(1)url
爬虫主要解析页面的url, 以及每个url页面的html标签(如head,body, div, p, a等)。首先对所要爬取的页面 url和内容的布局非常了解。
比如爬取凤凰网的所有新闻。 凤凰网大部分新闻正文的页面链接,都是这种形式:
可以用正则表达式把这些页面从新闻首页中提取出来
re_newsdetail = 'http://news.ifeng.com/a/[0-9]{8}/[0-9]{8}_0.shtml$'
(2)页面中的标签元素
我们主要提取的是新闻的标题和正文内容。 可以在浏览器(chrome)里用F12, 来观察页面布局。
比如凤凰网新闻正文页面, 标题都在<div id='artical'>中,是<h1>标签, 正文都在<div id='main_content'>里, 是<p>标签。
- 编写程序并调试
urllib负责对url的处理,主要是request, parse, error, 这几个模块。 负责对url发送请求,获取页面信息,error的处理。
Beautifulsoup负责对页面的解析,获取的页面是html树形结构, 通过findAll(), select(), get(), get_text()等函数即可很方便的获取到我们想要的内容。
4.最后,如果是想要获取整个门户网站的数据,则需要一些递归, 整个网站相当于一个图结构, dfs(深度优先遍历)是比较好的方法。
多级递归爬虫示例:
1#coding: utf-8
2
3import codecs
4from urllib import request, parse
5from bs4 import BeautifulSoup
6import re
7import time
8from urllib.error import HTTPError, URLError
9import sys
10
11###新闻类定义
12class News(object):
13 def __init__(self):
14 self.url = None #该新闻对应的url
15 self.topic = None #新闻标题
16 self.date = None #新闻发布日期
17 self.content = None #新闻的正文内容
18 self.author = None #新闻作者
19
20###如果url符合解析要求,则对该页面进行信息提取
21def getNews(url):
22 #获取页面所有元素
23 html = request.urlopen(url).read().decode('utf-8', 'ignore')
24 #解析
25 soup = BeautifulSoup(html, 'lxml')
26
27 #检查是否是 artical
28 if not(soup.find('div', {'id':'artical'})): return
29
30 news = News() #建立新闻对象
31
32 page = soup.find('div', {'id':'artical'}) #正文及标题
33
34 if not(page.find('h1', {'id':'artical_topic'})): return
35 #新闻标题
36 topic = page.find('h1', {'id':'artical_topic'}).get_text()
37 news.topic = topic
38
39 if not(page.find('div', {'id': 'main_content'})): return
40 #新闻正文内容
41 main_content = page.find('div', {'id': 'main_content'})
42
43 content = ''
44
45 #新闻内容
46 for p in main_content.select('p'):
47 content = content + p.get_text()
48 news.content = content news.url = url #新闻页面对应的url
49
50 f.write(news.topic+'\t'+news.content+'\n')
51
52##dfs算法遍历全站###
53def dfs(url):
54 #global count
55 print(url)
56 #可以继续访问的url规则
57 pattern1 = 'http://news\.ifeng\.com\/[a-z0-9_\/\.]*$'
58 #解析新闻信息的url规则
59 pattern2 = 'http://news\.ifeng\.com\/a\/[0-9]{8}\/[0-9]{8}\_0\.shtml$'
60 #该url访问过,则直接返回
61
62 if url in visited: return print(url)
63 #把该url添加进visited()
64 visited.add(url)
65
66 try: #该url没有访问过的话,则继续解析操作
67 html = request.urlopen(url).read().decode('utf-8', 'ignore')
68
69 ####提取该页面其中所有的url####
70 links = soup.findAll('a', href=re.compile(pattern1))
71
72 for link in links:
73 print(link['href'])
74 if link['href'] not in visited:
75 dfs(link['href']) #递归调用
76
77 except URLError as e:
78 print(e)
79 return
80 except HTTPError as e:
81 print(e)
82 return
83
84visited = set() ##存储访问过的url
85f = open('news.txt', 'a+', encoding='utf-8')
86
87dfs('http://news.ifeng.com/')
两级爬虫及简单的数据库操作示例:
1#coding: utf-8
2
3import codecs
4from urllib import request, parse
5from bs4 import BeautifulSoup
6import re
7import time
8from urllib.error import HTTPError, URLError
9import sys
10import json
11import pymysql
12
13# 打开数据库连接
14connect = pymysql.Connect(
15 host='localhost',
16 port=3306,
17 user='root',
18 passwd='yourpwd',
19 db='yourdb',
20 charset='utf8'
21)
22
23# 使用cursor()方法获取操作游标
24cursor = connect.cursor()
25
26# sql语句前半段
27sql = "INSERT INTO article(title,author,content,cover,description," \
28 "publishedtime,cid) VALUES "
29
30# 提取新闻内容
31def getDetails(url):
32
33 #获取页面所有元素
34 html = request.urlopen(url).read().decode('utf-8', 'ignore')
35
36 #解析
37 soup = BeautifulSoup(html, 'lxml')
38
39 #获取信息
40 if not(soup.find('div', {'id':'artical'})): return
41
42 page = soup.find('div', {'id':'artical'})
43
44 #print('*** analysis page start ***')
45
46 if not(page.find('h1', {'id':'artical_topic'})): return
47 #新闻标题
48 topic = page.find('h1', {'id':'artical_topic'}).get_text()
49
50 if not(page.find('div', {'id': 'main_content'})): return
51 #新闻正文内容
52 main_content = page.find('div', {'id': 'main_content'})
53
54 content = ''
55 if main_content.find('br'):
56 content = main_content.prettify()
57 else:
58 for p in main_content.select('p'):
59 if p.get_text() == '': continue
60 content += "<p>" +p.get_text()+"</p>"
61 content = content.replace("\'","")
62
63 #每个新闻内容页的js脚本中有一个json格式的新闻简介
64 #可以提取cover图片,新闻标题,摘要,类别等
65 for sc in soup.findAll("script"):
66 if '@TODO: 全局参数' in sc.prettify():
67 try:
68 detail = sc.prettify()
69 detail = detail.replace("\'","\"")
70 jsonStart = findStr(detail, '{', 2)
71 jsonEnd = detail.index('}')
72 detail = detail[jsonStart:jsonEnd]
73 jsonData = json.loads(detail+'}')
74 except:
75 return
76 author = '凤凰网'
77 title = topic
78 content = content
79 desc = jsonData['summary']
80 publishedtime = str(int(time.time()))
81 cid = '1'
82 cover = jsonData['image']
83
84 strSql.add(sql+"('"+title+"', '"+author+"','"+content+"','"+ \
85 cover+"','"+desc+"',"+publishedtime+","+cid+")")
86
87# 遍历新闻主页面
88def getNews(url):
89 global count
90 #解析新闻信息的url规则
91 pattern = 'http://news\.ifeng\.com\/a\/[0-9]{8}\/[0-9]{8}\_0\.shtml$'
92 try:
93 html = request.urlopen(url).read().decode('utf-8', 'ignore')
94 soup = BeautifulSoup(html, 'lxml')
95
96 # 提取该页面其中所有的url
97 links = soup.findAll('a', href=re.compile(pattern))
98
99 count = 1
100
101 for link in links:
102 if (count <= 30) :
103 print(link['href']+' **** count: '+str(count))
104 getDetails(link['href'])
105 count += 1
106 else: break
107
108 except URLError as e:
109 print(e)
110 return
111 except HTTPError as e:
112 print(e)
113 return
114
115#查找第N(findCnt)次出现的位置
116def findStr(string, subStr, findCnt):
117 listStr = string.split(subStr,findCnt)
118 if len(listStr) <= findCnt:
119 return -1
120 return len(string)-len(listStr[-1])-len(subStr)
121
122##############################################################
123strSql = set()
124today = time.strftime('%Y%m%d',time.localtime())
125#getDetails('http://news.ifeng.com/a/20180604/58574816_0.shtml')
126
127try:
128 getNews('http://news.ifeng.com/listpage/11502/'+today+'/1/rtlist.shtml')
129
130 for strsql in strSql:
131 # 执行sql语句
132 cursor.execute(strsql)
133 # 提交到数据库执行
134 connect.commit()
135 print('成功插入', len(strSql), '条数据')
136
137 cursor.close()
138
139except Exception as e:
140 cursor.close()
141 # 如果发生错误则回滚
142 connect.rollback()
143 print('事务处理失败', e)
144 # 关闭数据库连接
145 connect.close()
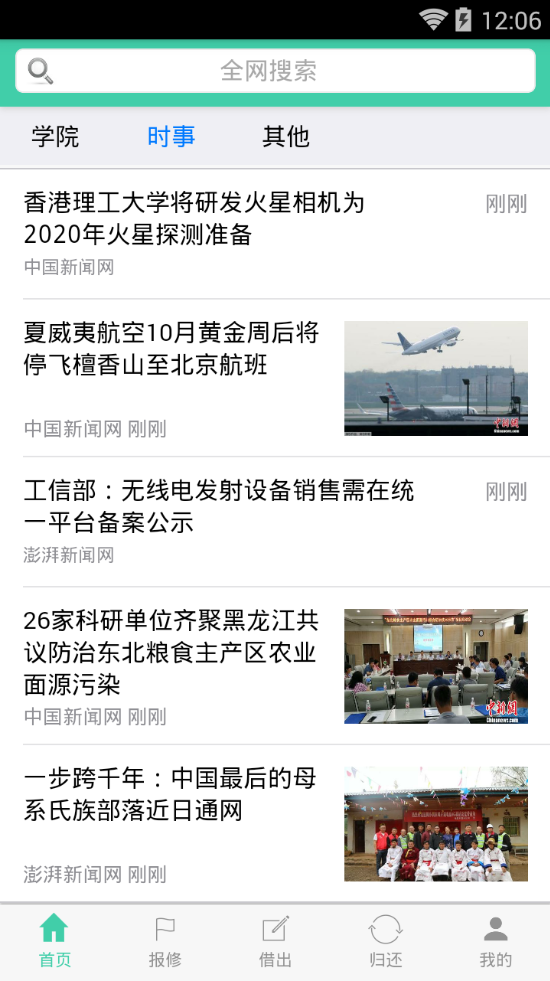
爬虫效果展示:
多级爬虫参考:https://blog.csdn.net/MrWilliamVs/article/details/76422584?locationNum=9&fps=1ss